

Unless you’ve spent the last 5 years asleep you know that every team, business, and industry is being turned upside down by AI. Every startup is trying to create the newest AI offering, every tech giant is trying to add LLM functionality everywhere, and every business is trying to replace employees with agents. But what does this mean for intelligence analysts? How can we use LLMs to help us with our work? And what are the limitations? Can we overcome them? Or are we just going to end up with a bunch of over hyped tools that don’t really help us at all?
While it’s easy to speculate, the reality is almost as easy to understand, simply by doing. As part of a talk I did on LLMs and Structured Analytic Techniques (SATs) for the SANS Emerging Threats Summit, I wanted to explore how LLMs can help with SATs. The goal was to build a series of simple tools that use LLMs to help with SATs, and then use those tools to see how they work in practice. If you want to see more about the presentation, specifically how I build it, check out my post on Building Security Talks in 2025. Here though I’m going to focus on the tools I built, and how they work in practice.
SATs with LLMs
The bulk of this exploration is about how analysts can use LLMs to help with SATs, especially for small teams. In my experience people are either way too optimistic or way too pessimistic about using LLMs for tasks like this. Rather than guess or suppose, the best approach is to simply try.
 Current Position: Unknown?!
Current Position: Unknown?!
To do this I’m started with Structured Analytic Techniques for Intelligence Analysis, a fantastic book originally written by Richards Heuer Jr and Randolph H. Pherson that outlines a variety of SATs. I want to focus on three SATs that I think are particularly relevant for LLMs: Starbursting, Analysis of Competing Hypothesis, and Key Assumptions Checks, and build simple tools to run these processes and then use them. The goal is not simply to have the LLMs do the work for me, but to use them as a tool to help me with the process, a human-machine team.
Architecture
Each of these three apps are built nearly the same way based on my preferred approach for testing AI tools: a simple web app that uses an LLM to generate text. The web app is built using Streamlit, a Python library for writing apps without HTML/CSS/JavaScript. For a model I used OpenAI’s GPT-4. There was no special reason for GPT-4, and this could easily be done using Gemini or Claude or even a local model, I just went with what was easy. To enforce structure and make future experiments easier I used LangChain and Pydantic to build the LLM queries. Each web app takes a SAT specific set of inputs (along with your OpenAI key), and then manages the process of executing the SAT via the LLM in a simplified way according to the Structured Analytic Techniques for Intelligence Analysis process.
Experiment #1 - Starbursting
Starbursting (These links go to a live version of the app you can try!) is an Idea Generation SAT that develops questions about a topic. It’s a great way to generate ideas and explore a topic and start defining the scope of a problem. It’s also a nice starting point as it’s a very simple SAT to implement.
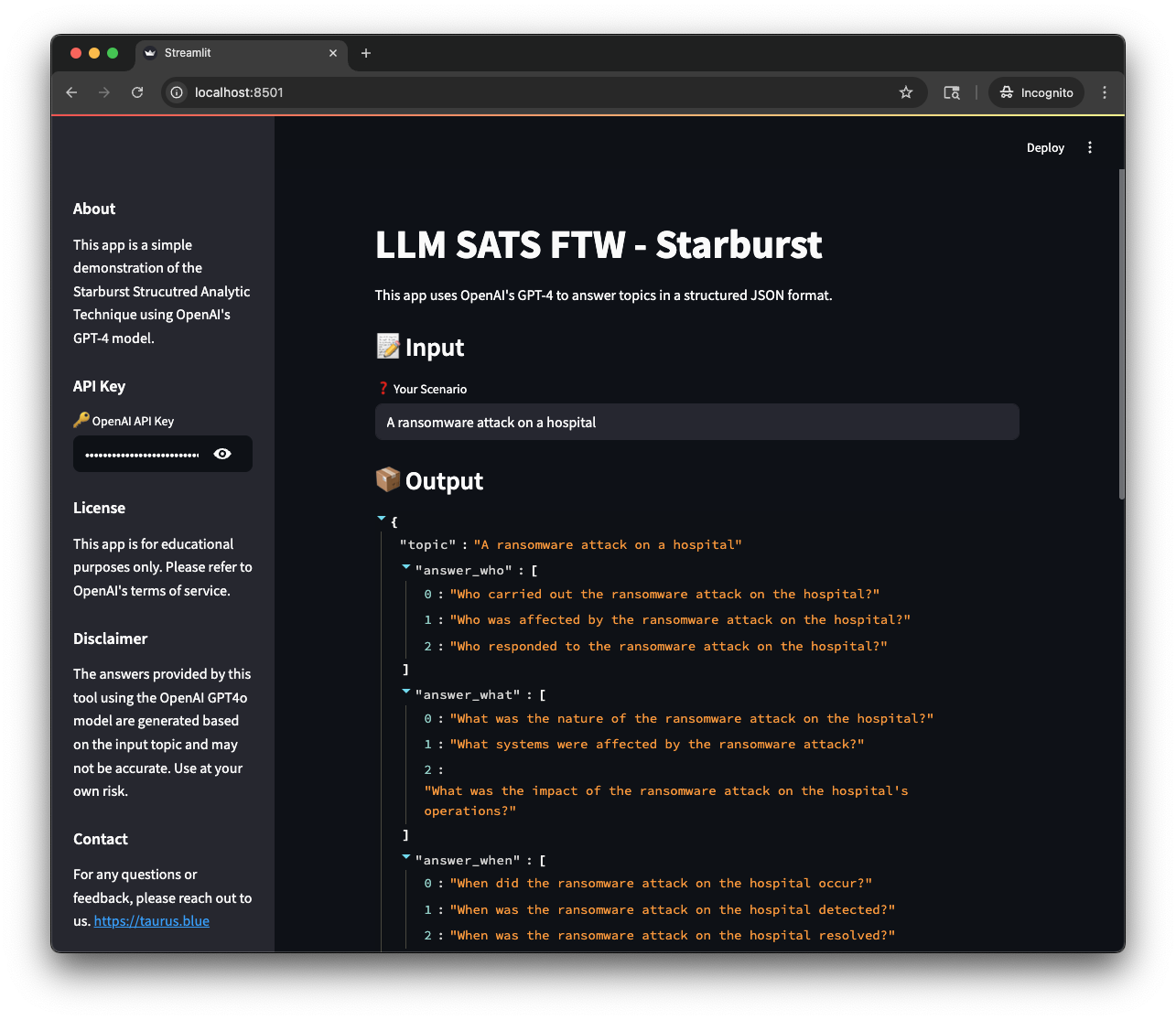
The process is simple: you start with a topic, and then generate a series of questions about that topic. The questions should be open-ended and exploratory, and should cover a variety of different aspects of the topic. The goal is to generate as many questions as possible, and then use those questions to explore the topic further.
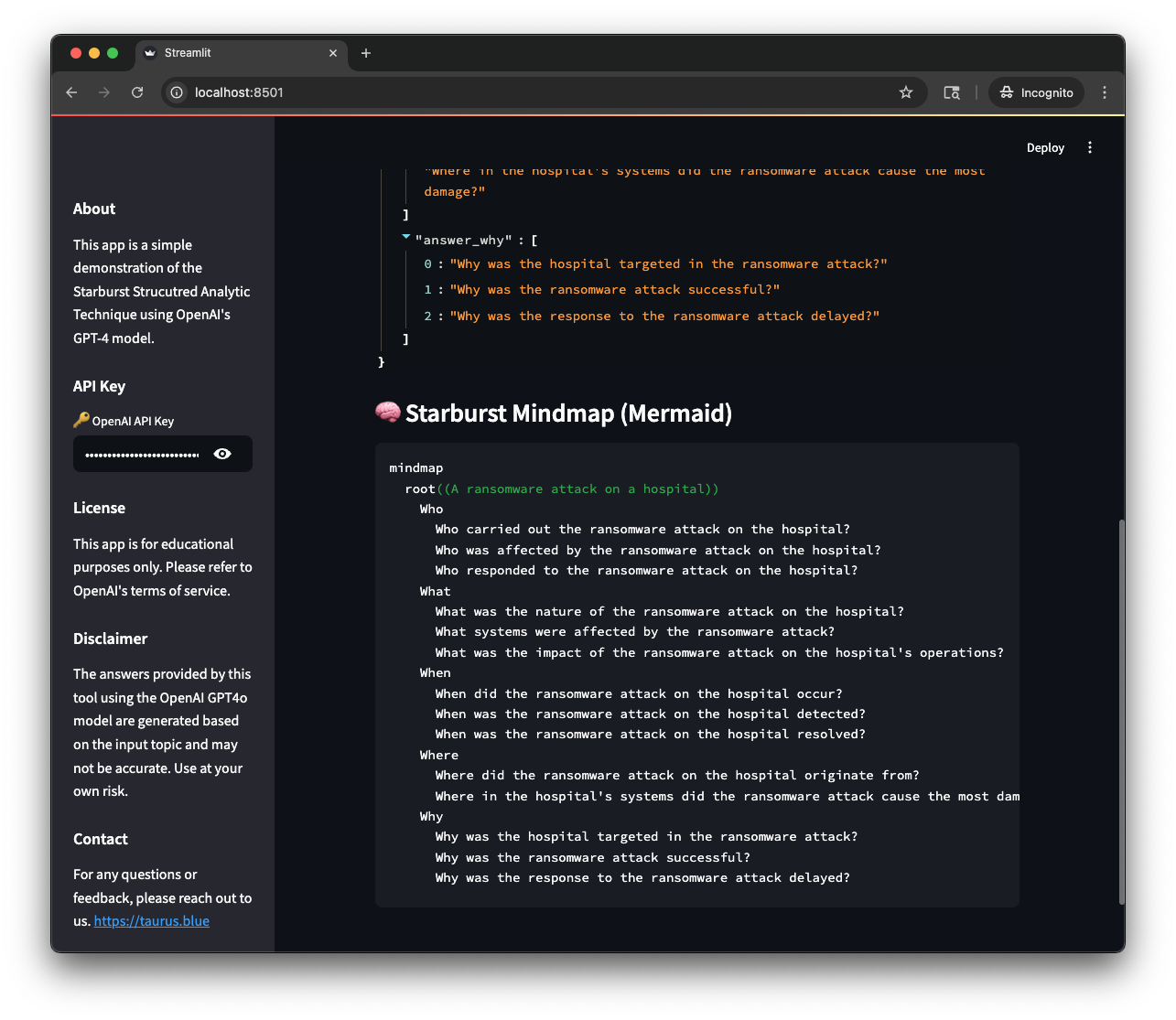
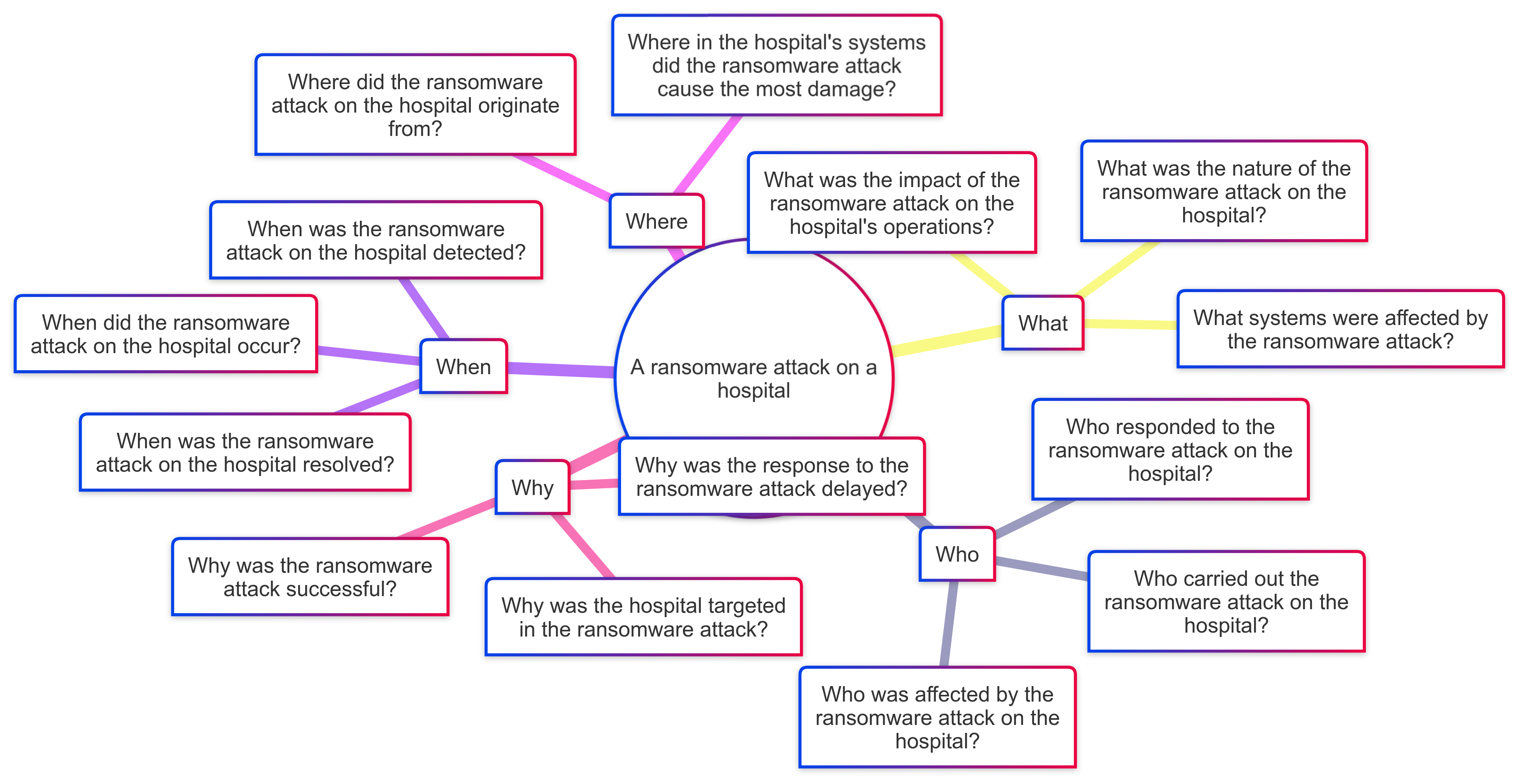
One of the best things about using a text driven method, like an LLM to generate content is you can use other tools to visualize the content. In this case I used Mermaid to generate a mind map of the questions. This is a great way to visualize the questions and see how they relate to each other.
mindmap
mindmap
root((A ransomware attack on a hospital))
Who
Who carried out the ransomware attack on the hospital?
Who was affected by the ransomware attack on the hospital?
Who responded to the ransomware attack on the hospital?
What
What was the nature of the ransomware attack on the hospital?
What systems were affected by the ransomware attack?
What was the impact of the ransomware attack on the hospital's operations?
When
When did the ransomware attack on the hospital occur?
When was the ransomware attack on the hospital detected?
When was the ransomware attack on the hospital resolved?
Where
Where did the ransomware attack on the hospital originate from?
Where in the hospital's systems did the ransomware attack cause the most damage?
Why
Why was the hospital targeted in the ransomware attack?
Why was the ransomware attack successful?
Why was the response to the ransomware attack delayed?
In case you’re wondering this renders as:
Experiment #2 - Analysis of Competing Hypotheses (ACH)
Ahhh Analysis of Competing Hypotheses, the classic SAT. The process is simple: you start with a topic and generate a series of hypotheses. The hypotheses should be open-ended and exploratory, and should cover a variety of different aspects of the topic. Once you’ve got hypotheses, you find evidence for and against each hypothesis, and then use that evidence to evaluate the hypotheses. All of them. You can then total the numbers up and see which hypothesis has the most evidence for it.
ACH is a vastly different beast than Starbursting, both for analysts and for an LLM. Where Starbursting is a simple SAT that can be done in a few minutes, ACH is a complex SAT that takes teams hours or even days to complete. The process is simple, but the execution is complex, and many teams of analysts struggle with it.
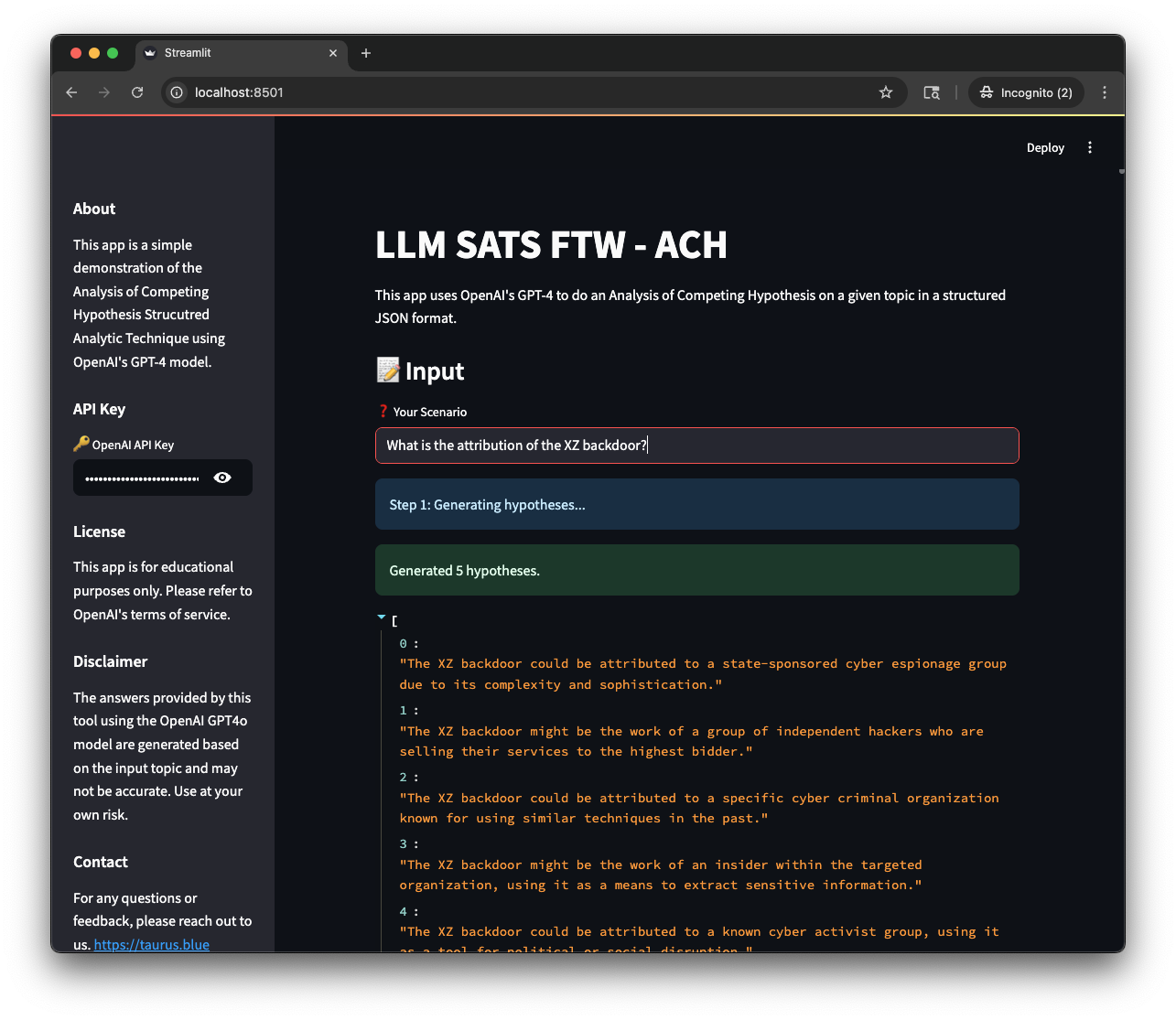
Again, built with Streamlit, but while the analyst still only sends one request this isn’t a “zero shot” approach based on one query like the Starbursting SAT, ACH is actually many queries to the LLM. These aren’t static queries either, as the queries are based on responses to the earlier responses.
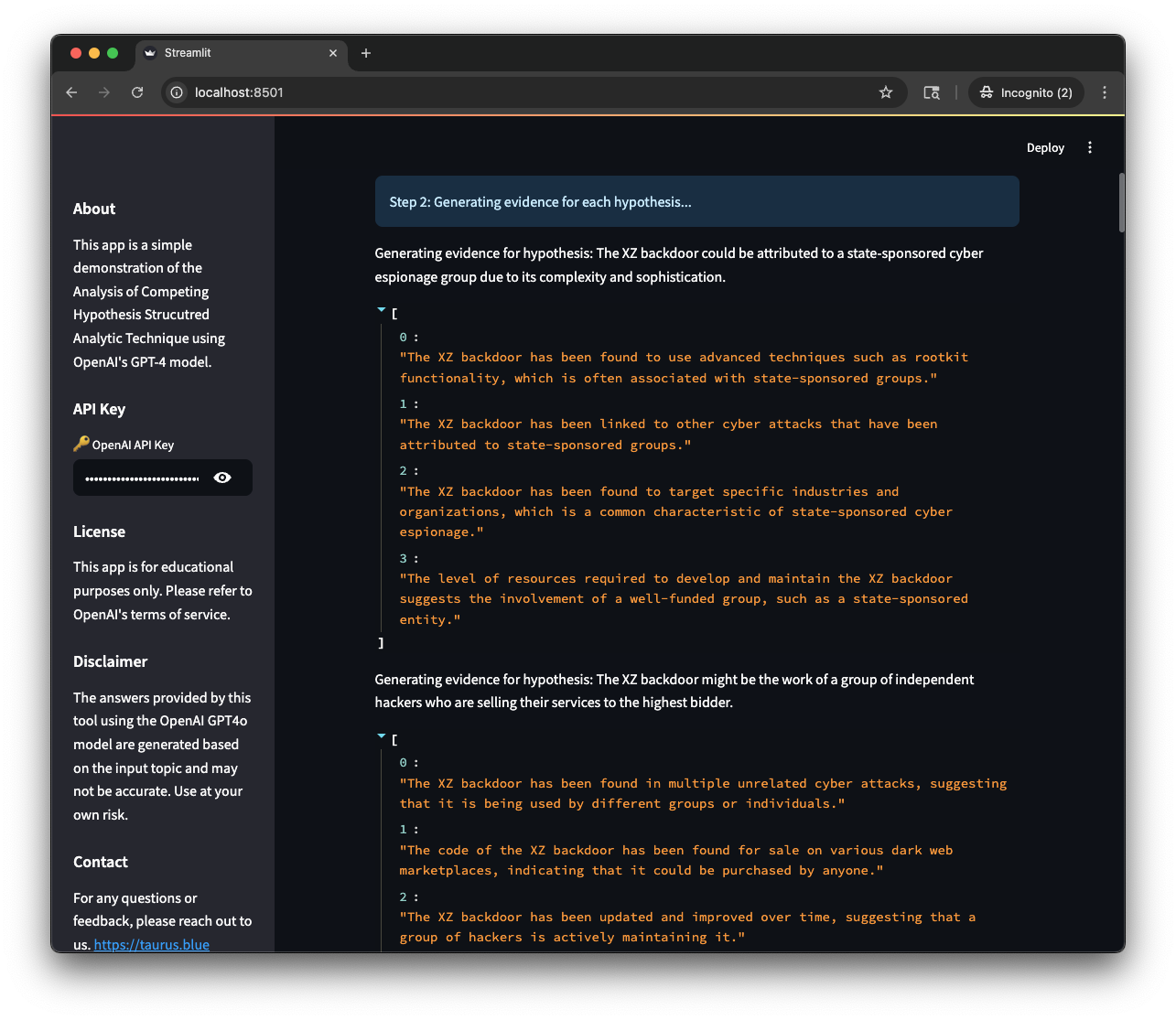
Technically this isn’t a “few shot” approach, it’s actually multiple “zero shot” queries, but I think of it as a “few shot” approach because the LLM is generating the queries based on the previous responses. It’s a subtle difference, but an important one.
To start the analyst submits their initial question, usually something complex and nuanced like attribution, and then we ask the LLM to generate a series of hypotheses about that topic as a list of strings. The hypotheses should be open-ended and exploratory, and should cover a variety of different aspects of the topic. Once we’ve got hypotheses, we send another set of requests to the LLM to generate evidence for and against each hypothesis. Almost there, now we let the LLM do some evaluation, sending individual queries with each hypothesis and evidence, and asking for a score (in our case -5 (strongly against) to +5 (strongly for)). Finally we total the numbers up and see which hypothesis has the most evidence for it and output it as a table.
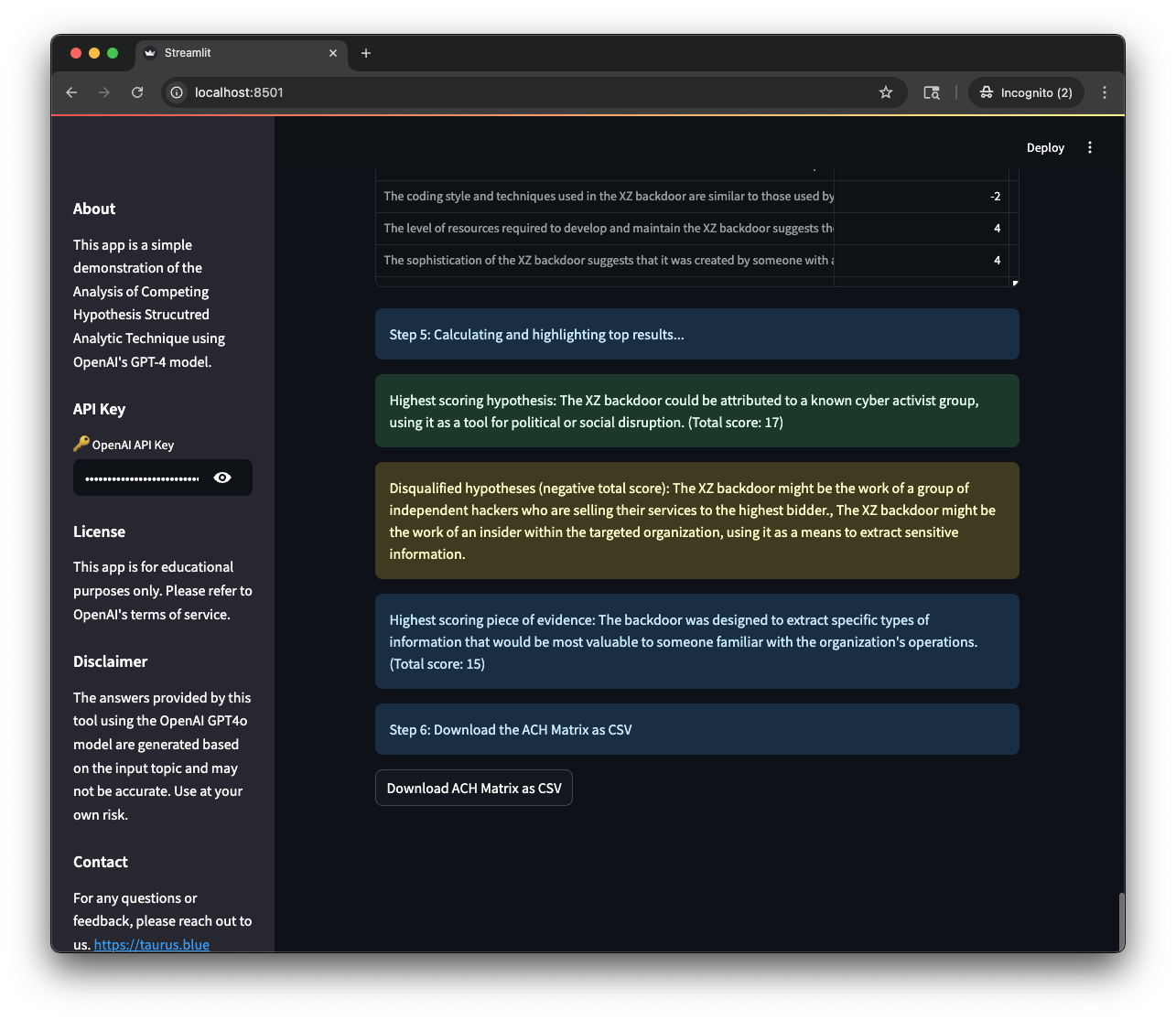
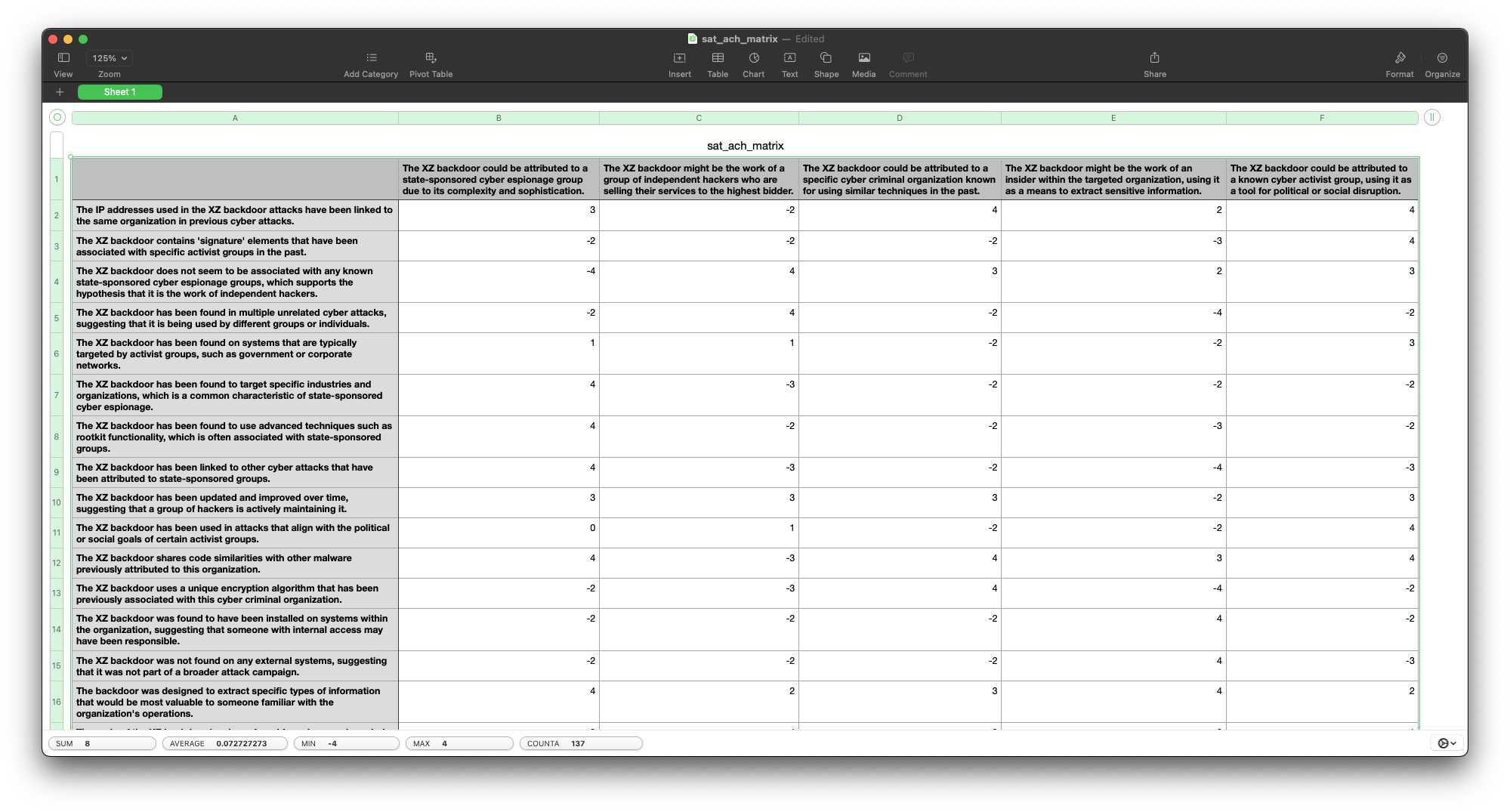
This is a great case to show how we can use an LLM to enhance a human analyst, rather than replace them. So I added one more step: The tool then shares a CSV with the analyst. The analyst can then use the CSV to review the results, add evidence, modify scores, and make a decision about which hypothesis to pursue. This is a great way to show how LLMs can help with the human side of things, especially for small teams.
Experiment #3 - Key Assumptions Check
Lastly, my BFFFCL’s (it’s my blog, I can use random intelligence analysis centric inside jokes if I want) favorite SAT: Key Assumptions Check. This rounds out moving from a pre-analysis SAT (Starbursting) to a mid-analysis SAT (ACH) to a post-analysis SAT meant for double checking your own analysis after the fact for biases and bad assumptions.
Yet again, Streamlit made it easy to build out something basic, but effective. In this case we’re back to a “zero shot” approach, but instead of an analyst posted question we’re using a finished intelligence product, as a PDF, reading that in, extracting the text, and asking the LLM to identify a series of assumptions in the text.
Interestingly here I ran into a technical limitation of the LLM: too many tokens. I had to break the PDF into chunks, and then ask the LLM to identify the assumptions in each chunk. On one hand it’s an easy fix, but it shows the issues with relying on LLMs alone.
As a starting example I used Strider’s excellent report “Inside the Shadow Network: North Korean IT Workers in Russia and Their PRC Backers”. The tool extracts the text from the PDF, and then asks the LLM to identify the assumptions in the text.
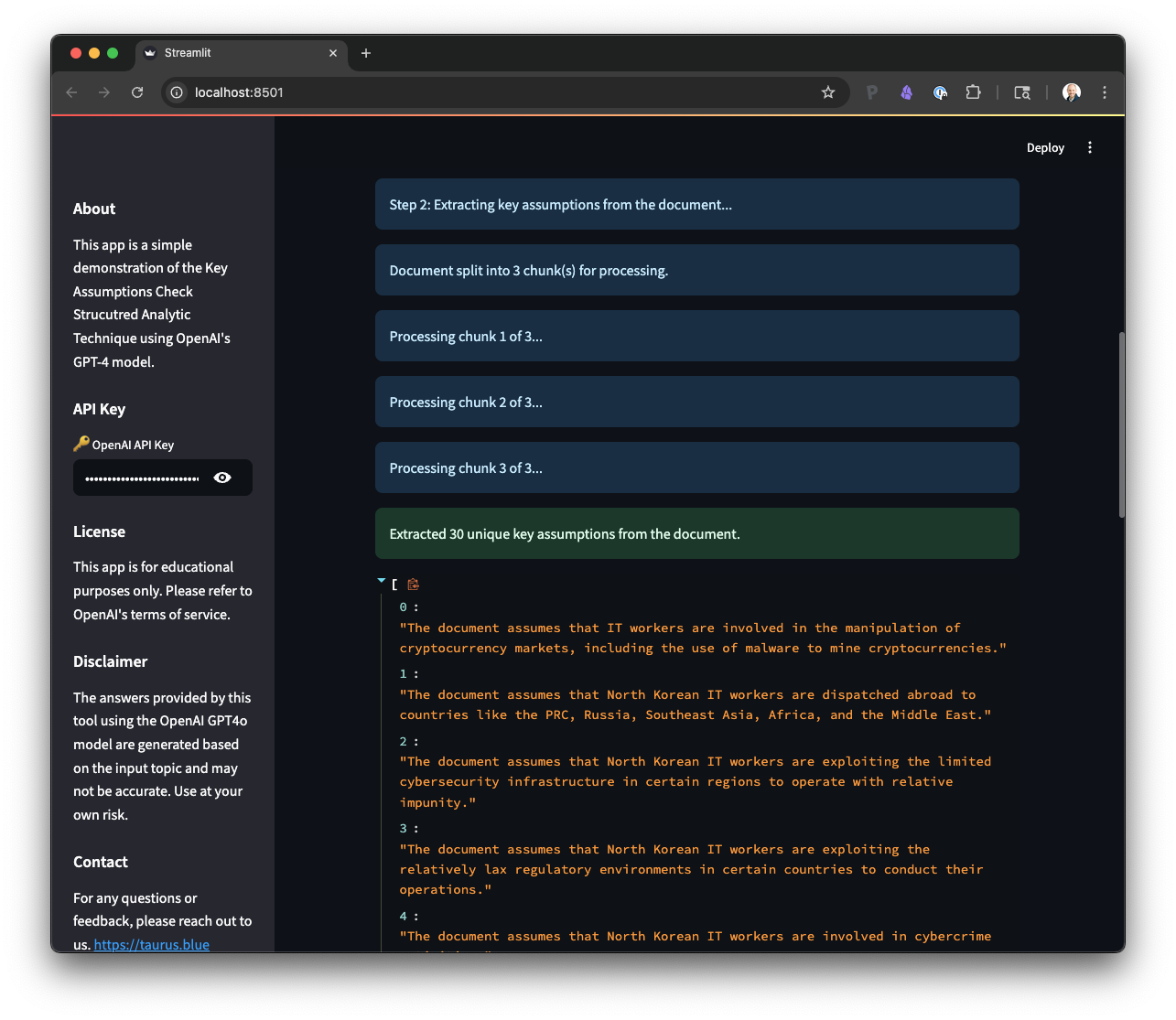
It’s key to remember that assumptions are not wrong, everyone has them, but they can be wrong. The goal of this SAT is to identify those assumptions and then evaluate them, just to ensure that these assumptions are a strong foundation.
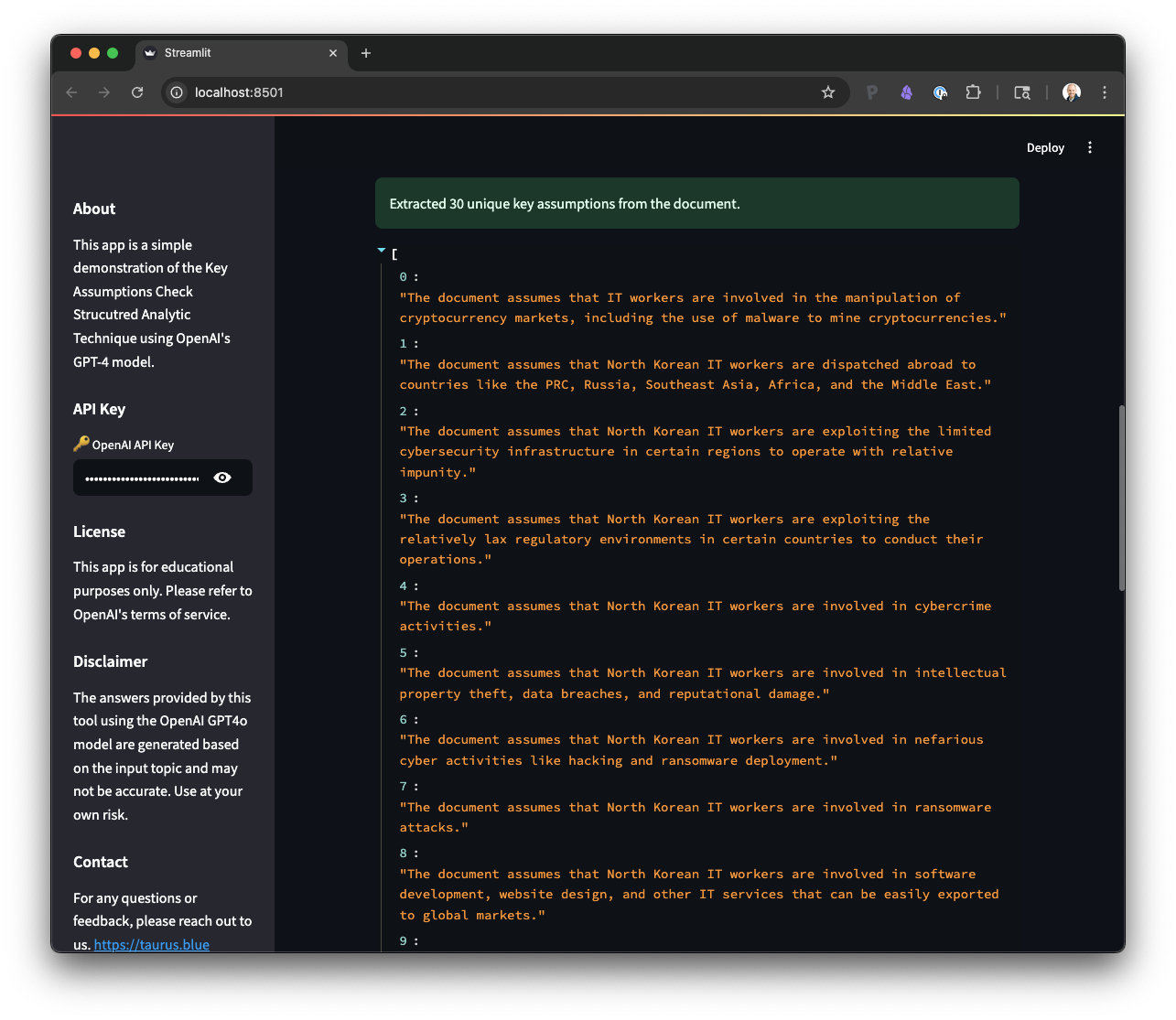
This netted 30 assumptions of varying quality, but it was a great starting point. The LLM did a good job of identifying assumptions, but often missed things that were found in evidence in other parts of the report. This is a great example of how LLMs can help, but rarely replace, human analysts.
Conclusion
Well… as so many things in intelligence analysis, it depends. LLMs are a great tool to help with SATs, but they are not a replacement for human analysts. They can help with the process, but they cannot replace the human side of things. The tools I built are simple, but effective, and show how LLMs can be used to enhance the human side of things. I hope this post has given you some ideas about how you can use LLMs to help with your own work.
Are these tools a good replacement for a large team of analysts with plenty of mental cycles to spend on analysis? No. But they are a great way to help small teams of analysts, or even individual analysts, to get started with SATs and LLMs. I hope this post has given you some ideas about how you can use LLMs to help with your own work. There was a quote I heard on the Ezra Kline show (discussing AI tools in education): “An AI system doesn’t have to be better than a human, just better than the best available human”. I’ve worked in many organizations where there was no other human available, or an overworked, stressed out human. In those cases, LLMs are a great tool to help with SATs, and can be used to enhance the human side of things. I hope this post has given you some ideas about how you can use LLMs to help with your own work.
| SAT | Description | App Link | Code Link |
|---|---|---|---|
| Starbursting | Idea Generation SAT that develops questions about a topic | Starbursting | Starbursting Code |
| ACH | Analysis of Competing Hypotheses SAT that generates hypotheses and evaluates them | ACH | ACH Code |
| Key Assumptions Check | SAT that identifies assumptions in a finished intelligence product | Key Assumptions Check | Key Assumptions Check Codes |
Presentation
This was part of a talk I did at the SANS Emerging Threats Summit. If you want to see more about the presentation, specifically how I build it, check out my post on Building Security Talks in 2025.